
Computer Vision 101 - A Practical Guide to Start with Computer Vision
A Practical Guide to Start with Computer Vision
If We Want Machines to Think, We Need to Teach Them to See.
-Fei Fei Li, Director of Stanford AI Lab and Stanford Vision Lab.
Why This Post??
As an undergraduate, I have fascinated, dreamed, worked and learnt much from Internet. We hear terms like Machine Learning, Computer Vision, AI….. everyday but how to actually get started with all these? This post is to introduce you to basics of Computer Vision.
The technology that makes machines such as computers or mobile phones see the surroundings is known as Computer Vision. Serious work on re-creating a human eye started way back in 50s and since then, we have come a long way. Computer vision has already made its way to our mobile phone via different e-commerce or camera apps.
Think of what more can be done by machine when they will be able to see as accurate as a human eye. Human eye is a complex structure and it goes through more complex phenomenon of understanding the environment. In a similar fashion, making machines see things and make them capable enough to figure out what they are seeing and further categorize it, is still a pretty tough job.
Working on Computer Vision is equivalent to working on millions of calculations in the blink of an eye with almost same accuracy as that of a human eye. It is not just about converting a picture into pixels, and then try to make sense of what’s in the picture through those pixels, you will have to first understand the bigger picture of how to extract information from those pixels and understand what they represent.
How do machines see? Let’s Dive in!
- CS Legacy. Represent Colors by number: In computer science, each color is represented by a specified HEX value. That is how machines are programmed to understand what colors the image pixels are made up. Whereas as humans we have an inherited knowledge to differ between the shades.
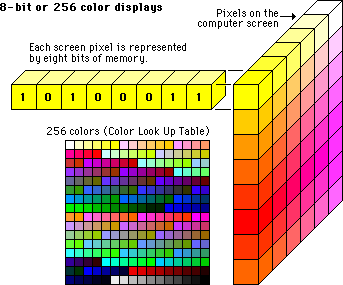
- Image Segmentation: Computers are made to identify similar group of colors and then segment the image i.e. distinguish the foreground from background. The technique of color gradient is used to find edges of different objects.

-
Finding corners: After segmentation, images are then looked up for certain features, also known as corners. In simple words, algorithms search for lines that meet at an angle and cover a specific part of the image with one color shade. Features, also called corners are the building blocks which help to find more detailed information contained in the image.
-
Find textures: Another important aspect to identify any image correctly is to determine the texture in the image. The difference in textures between two objects makes it easier for a machine to correctly categorize an object.
-
Make a guess: After implementing the above steps, a machine needs to make a nearly-right guess and match the image with those present in the database.

- Finally: See the bigger picture! At last, a machine sees the bigger and clear picture and checks if it was right identifying the one, as per the feeded algorithmic instructions. The accuracy has improved a lot in past years but still, machines make mistakes when asked to handle images with mixed objects.
Prerequisites.
Beginner level
A. Mathematics :
- Linear Algebra
- Singular Value Decomposition
- Introductory level Pattern Recognition
- Principal Component Analysis
- Kalman filtering
- Fourier Transform
- Wavelets
B. Image Processing:
- Online Course offered by Duke University on Coursera
- Digital Image Processing by Gonzalez and Woods
Advanced level
- Linear Discriminant Analysis
- Probability, Bayes rule, Maximum Likelihood, MAP
- Mixtures and Expectation-Maximization Algorithm
- Introductory level Statistical Learning
- Support Vector Machines
- Genetic Algorithms
- Hidden Markov Models
- Bayesian Networks
Theoretical Parts are alright, Now when we have to implement we have to move to softwares frameworks and tools
- Octave / MATLAB
- OpenCV (C++/Python)
There are some awesome moocs which are available freely on Internet:
- Udacity : Introduction to Computer Vision
- Stanford’s CS231n: Convolutional Neural Networks for Visual Recognition Visit there Youtube Channel for Videos.
Check Awesome Computer Vision Repository which has more resources.


Leave a Comment